



- дё»еә“Aжү§иЎҢе®ҢжҲҗдёҖдёӘдәӢеҠЎпјҢ еҶҷе…Ҙbinlog пјҢи®°дёә T1
- 然еҗҺдј з»ҷд»Һеә“BпјҢд»Һеә“B жҺҘ收иҜҘbinlog пјҢи®°дёә T2
- д»Һеә“Bжү§иЎҢе®ҢжҲҗиҝҷдёӘдәӢеҠЎпјҢи®°дёә T3
- еҗҢжӯҘ延时пјҡ T3-T1
- еҗҢдёҖдёӘдәӢеҠЎпјҢеңЁ д»Һеә“жү§иЎҢе®ҢжҲҗзҡ„ж—¶й—ҙ е’Ң дё»еә“жү§иЎҢе®ҢжҲҗзҡ„ж—¶й—ҙ д№Ӣй—ҙзҡ„е·®еҖј
- SHOW SLAVE STATUS дёӯзҡ„ Seconds_Behind_Master
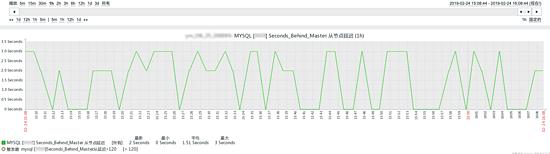
Seconds_Behind_Master
- и®Ўз®—ж–№жі•
- жҜҸдёӘдәӢеҠЎзҡ„ binlog йҮҢйқўйғҪжңүдёҖдёӘ ж—¶й—ҙеӯ—ж®ө пјҢз”ЁдәҺи®°еҪ•иҜҘ binlog еңЁ дё»еә“ дёҠзҡ„еҶҷе…Ҙж—¶й—ҙ
- д»Һеә“еҸ–еҮәеҪ“еүҚжӯЈеңЁжү§иЎҢзҡ„дәӢеҠЎзҡ„ж—¶й—ҙеӯ—ж®өзҡ„еҖјпјҢи®Ўз®—е®ғдёҺеҪ“еүҚзі»з»ҹж—¶й—ҙзӮ№е·®еҖјпјҢеҫ—еҲ° Seconds_Behind_Master
- еҚі T3-T1
- еҰӮжһңдё»еә“дёҺд»Һеә“зҡ„ж—¶й—ҙдёҚдёҖиҮҙпјҢ Seconds_Behind_Master дјҡдёҚдјҡжңүиҜҜе·®пјҹ
- дёҖиҲ¬дёҚдјҡ
- еңЁ д»Һеә“иҝһжҺҘеҲ°дё»еә“ ж—¶пјҢдјҡйҖҡиҝҮ SELECT UNIX_TIMESTAMP() иҺ·еҸ– еҪ“еүҚдё»еә“зҡ„зі»з»ҹж—¶й—ҙ
- еҰӮжһң д»Һеә“ еҸ‘зҺ° еҪ“еүҚдё»еә“зҡ„зі»з»ҹж—¶й—ҙ дёҺиҮӘе·ұзҡ„дёҚдёҖиҮҙпјҢеңЁи®Ўз®— Seconds_Behind_Master дјҡ иҮӘеҠЁжүЈйҷӨ иҝҷйғЁеҲҶе·®еҖј
- дҪҶе»әз«ӢиҝһжҺҘеҗҺпјҢдё»еә“жҲ–д»Һеә“еҸҲдҝ®ж”№дәҶзі»з»ҹж—¶й—ҙпјҢдҫқ然дјҡдёҚеҮҶзЎ®
- еңЁ зҪ‘з»ңжӯЈеёё зҡ„жғ…еҶөдёӢпјҢ T2-T1 йҖҡеёёдјҡйқһеёёе°ҸпјҢжӯӨж—¶еҗҢжӯҘ延时зҡ„дё»иҰҒжқҘжәҗжҳҜ T3-T2
- д»Һеә“ж¶Ҳиҙ№ relaylog зҡ„йҖҹеәҰи·ҹдёҚдёҠдё»еә“з”ҹжҲҗ binlog зҡ„йҖҹеәҰ
延时жқҘжәҗ
- д»Һеә“жүҖеңЁ жңәеҷЁзҡ„жҖ§иғҪ иҰҒејұдәҺдё»еә“жүҖеңЁзҡ„жңәеҷЁ
- жӣҙж–°иҜ·жұӮеҜ№дәҺIPOSзҡ„еҺӢеҠӣ пјҢеңЁ дё»еә“ е’Ң д»Һеә“ дёҠжҳҜ ж— е·®еҲ« зҡ„
- йқһеҜ№з§°йғЁзҪІ пјҡ20дёӘдё»еә“ж”ҫеңЁ4дёӘжңәеҷЁдёҠпјҢдҪҶжүҖжңүд»Һеә“ж”ҫеңЁдёҖдёӘжңәеҷЁдёҠ
- дё»д»Һд№Ӣй—ҙеҸҜиғҪдјҡ йҡҸж—¶еҲҮжҚў пјҢзҺ°еңЁдёҖиҲ¬йғҪдјҡйҮҮз”Ё зӣёеҗҢи§„ж јзҡ„жңәеҷЁ + еҜ№з§°йғЁзҪІ
- д»Һеә“еҺӢеҠӣеӨ§
- еёёи§ҒеңәжҷҜпјҡз®ЎзҗҶеҗҺеҸ°зҡ„жҹҘиҜўиҜӯеҸҘ
- д»Һеә“дёҠзҡ„жҹҘиҜўиҖ—иҙ№еӨ§йҮҸзҡ„ CPUиө„жәҗ е’Ң IOиө„жәҗ пјҢеҪұе“ҚдәҶеҗҢжӯҘйҖҹеәҰпјҢйҖ жҲҗдәҶ еҗҢжӯҘ延时
- и§ЈеҶіж–№жЎҲ
- дёҖдё»еӨҡд»Һ пјҢеҲҶжӢ…иҜ»еҺӢеҠӣпјҢдёҖиҲ¬йғҪдјҡйҮҮз”Ё
- йҖҡиҝҮ binlog иҫ“еҮәеҲ° еӨ–йғЁзі»з»ҹ пјҢдҫӢеҰӮHadoop
- еӨ§дәӢеҠЎ
- дё»еә“дёҠеҝ…йЎ»зӯүеҫ… дәӢеҠЎжү§иЎҢе®ҢжҲҗ еҗҺжүҚдјҡеҶҷе…Ҙ binlog пјҢеҶҚдј з»ҷд»Һеә“
- еёёи§ҒеңәжҷҜ1пјҡ дёҖж¬ЎжҖ§еҲ йҷӨеӨӘеӨҡж•°жҚ® пјҲеҰӮеҪ’жЎЈзҡ„еҺҶеҸІж•°жҚ®пјү
- и§ЈеҶіж–№жЎҲпјҡжҺ§еҲ¶жҜҸдёӘдәӢеҠЎеҲ йҷӨзҡ„ж•°жҚ®йҮҸпјҢеҲҶеӨҡж¬ЎеҲ йҷӨ
- еёёи§ҒеңәжҷҜ2пјҡ еӨ§иЎЁDDL
- и§ЈеҶіж–№жЎҲпјҡ gh-ost
- д»Һеә“зҡ„ 并иЎҢеӨҚеҲ¶иғҪеҠӣ пјҲеҗҺз»ӯеұ•ејҖпјү
еҲҮжҚўзӯ–з•Ҙ
еҸҜйқ жҖ§дјҳе…Ҳ
еҲҮжҚўиҝҮзЁӢдёҖиҲ¬з”ұдё“й—Ёзҡ„ HA зі»з»ҹе®ҢжҲҗпјҢеӯҳеңЁ дёҚеҸҜз”Ёж—¶й—ҙ пјҲдё»еә“Aе’Ңд»Һеә“BйғҪеӨ„дәҺ еҸӘиҜ» зҠ¶жҖҒпјү
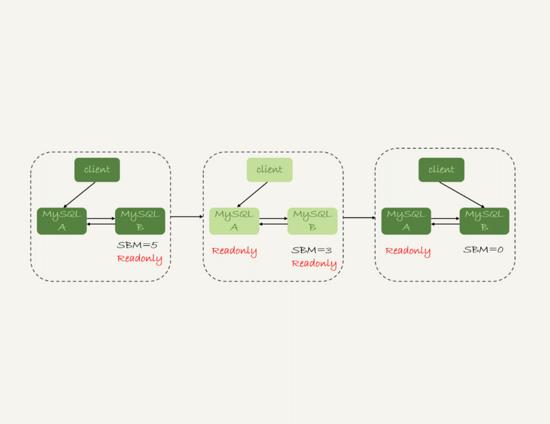
- еҲӨж–ӯ д»Һеә“B зҡ„ Seconds_Behind_Master еҖјпјҢеҪ“ е°ҸдәҺ жҹҗдёӘеҖјпјҲдҫӢеҰӮ5пјүжүҚ继з»ӯдёӢдёҖжӯҘ
- жҠҠ дё»еә“A ж”№дёә еҸӘиҜ» зҠ¶жҖҒпјҲ readonly=true пјү
- зӯүеҫ… д»Һеә“B зҡ„ Seconds_Behind_Master еҖјйҷҚдёә 0
- жҠҠ д»Һеә“B ж”№дёә еҸҜиҜ»еҶҷ зҠ¶жҖҒпјҲ readonly=false пјү
- жҠҠ дёҡеҠЎиҜ·жұӮ еҲҮжҚўиҮі д»Һеә“B
еҸҜз”ЁжҖ§дјҳе…Ҳ
дёҚзӯүдё»д»ҺеҗҢжӯҘе®ҢжҲҗпјҢ зӣҙжҺҘжҠҠдёҡеҠЎиҜ·жұӮеҲҮжҚўиҮід»Һеә“B пјҢ并且让 д»Һеә“BеҸҜиҜ»еҶҷ пјҢиҝҷж ·еҮ д№ҺдёҚеӯҳеңЁдёҚеҸҜз”Ёж—¶й—ҙпјҢдҪҶеҸҜиғҪдјҡ ж•°жҚ®дёҚдёҖиҮҙ
иЎЁеҲқе§ӢеҢ–
CREATE TABLE `t` ( `id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT, `c` INT(11) UNSIGNED DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; INSERT INTO t (c) VALUES (1),(2),(3);
жҸ’е…Ҙж•°жҚ®
INSERT INTO t (c) VALUES (4); -- дё»еә“дёҠзҡ„е…¶е®ғиЎЁжңүеӨ§йҮҸзҡ„жӣҙж–°пјҢеҜјиҮҙеҗҢжӯҘ延时дёә5SпјҢжҸ’е…Ҙc=4еҗҺеҸ‘иө·дәҶдё»д»ҺеҲҮжҚў INSERT INTO t (c) VALUES (5);
MIXED
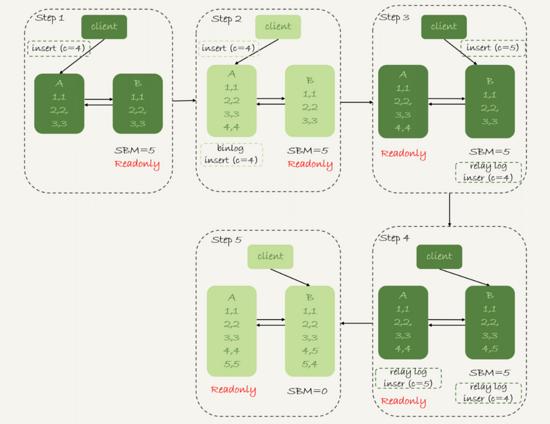
- дё»еә“Aжү§иЎҢе®Ң INSERT c=4 пјҢеҫ—еҲ° (4,4) пјҢ然еҗҺејҖе§Ӣжү§иЎҢ дё»д»ҺеҲҮжҚў
- дё»д»Һд№Ӣй—ҙжңү5Sзҡ„еҗҢжӯҘ延иҝҹпјҢд»Һеә“Bдјҡе…Ҳжү§иЎҢ INSERT c=5 пјҢеҫ—еҲ° (4,5) пјҢ并且дјҡжҠҠиҝҷдёӘ binlog еҸ‘з»ҷдё»еә“A
- д»Һеә“Bжү§иЎҢдё»еә“Aдј иҝҮжқҘзҡ„ INSERT c=4 пјҢеҫ—еҲ° (5,4)
- дё»еә“Aжү§иЎҢд»Һеә“Bдј иҝҮжқҘзҡ„ INSERT c=5 пјҢеҫ—еҲ° (5,5)
- жӯӨж—¶дё»еә“Aе’Ңд»Һеә“Bдјҡжңү дёӨиЎҢ дёҚдёҖиҮҙзҡ„ж•°жҚ®
ROW
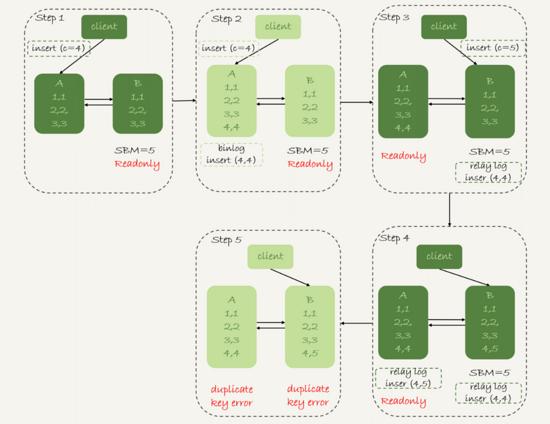
- йҮҮз”Ё ROW ж јејҸзҡ„ binlog ж—¶пјҢдјҡи®°еҪ•ж–°жҸ’е…ҘиЎҢзҡ„ жүҖжңүеӯ—ж®өзҡ„еҖј пјҢжүҖд»ҘжңҖеҗҺеҸӘдјҡжңү дёҖиЎҢ ж•°жҚ®дёҚдёҖиҮҙ
- дё»еә“Aе’Ңд»Һеә“Bзҡ„еҗҢжӯҘзәҝзЁӢйғҪдјҡ жҠҘй”ҷ并еҒңжӯў пјҡ duplicate key error
е°Ҹз»“
- дҪҝз”Ё ROW ж јејҸзҡ„ binlog пјҢж•°жҚ®дёҚдёҖиҮҙзҡ„й—®йўҳ жӣҙе®№жҳ“еҸ‘зҺ° пјҢйҮҮз”Ё MIXED жҲ– STATEMENT ж јејҸзҡ„ binlog пјҢж•°жҚ®еҸҜиғҪжӮ„жӮ„ең°дёҚдёҖиҮҙ
- дё»д»ҺеҲҮжҚўйҮҮз”Ё еҸҜз”ЁжҖ§дјҳе…Ҳ зӯ–з•ҘпјҢеҸҜиғҪдјҡеҜјиҮҙ ж•°жҚ®дёҚдёҖиҮҙ пјҢеӨ§еӨҡж•°жғ…еҶөдёӢпјҢдјҳе…ҲйҖүжӢ© еҸҜйқ жҖ§дјҳе…Ҳ зӯ–з•Ҙ
- еңЁж»Ўи¶і ж•°жҚ®еҸҜйқ жҖ§ зҡ„еүҚжҸҗдёӢпјҢMySQLзҡ„ еҸҜз”ЁжҖ§ дҫқиө–дәҺ еҗҢжӯҘ延时 зҡ„еӨ§е°ҸпјҲ еҗҢжӯҘ延时и¶Ҡе°Ҹ пјҢ еҸҜз”ЁжҖ§и¶Ҡй«ҳ пјү
жғіе…Қиҙ№еӯҰд№ Javaе·ҘзЁӢеҢ–гҖҒеҲҶеёғејҸжһ¶жһ„гҖҒй«ҳ并еҸ‘гҖҒй«ҳжҖ§иғҪгҖҒж·ұе…Ҙжө…еҮәгҖҒеҫ®жңҚеҠЎжһ¶жһ„гҖҒSpringпјҢMyBatisпјҢNettyжәҗз ҒеҲҶжһҗзӯүжҠҖжңҜзҡ„жңӢеҸӢпјҢеҸҜд»ҘеҠ зҫӨпјҡ834962734пјҢзҫӨйҮҢжңүйҳҝйҮҢеӨ§зүӣзӣҙж’ӯи®Іи§ЈжҠҖжңҜпјҢд»ҘеҸҠJavaеӨ§еһӢдә’иҒ”зҪ‘жҠҖжңҜзҡ„и§Ҷйў‘е…Қиҙ№еҲҶдә«з»ҷеӨ§е®¶пјҢж¬ўиҝҺиҝӣзҫӨдёҖиө·ж·ұе…ҘдәӨжөҒеӯҰд№ гҖӮ

